How Pando Meetings Drive Continuous Calibration
How meetings can drive structured performance based checkins to keep employees performance on track.
Read moreCareer frameworks, feedback and goals to structure, measure and accelerate business impact.
Request demo



Pando helps companies increase ramp time, develop high performers and retain talent through continuous growth and career progression.




Pando reduces bias and subjectivity in feedback and reviews, making career advancement equitable for all employees.
Read more ⭢


Modern, agile and employee-first.

Employee triggered, short form assessments to track progress against goals and professional achievements.
Learn more

Templitized career check-ins, competency-based feedback, and real-time calibrations to help managers become better coaches.
Learn moreNo need for performance reviews, with Pando, you can track employee and team performance in real-time.
Learn more




%201.webp)

Pando makes career progression accessible so employees can continuously level-up and track their impact as they grow.
Learn more ⭢
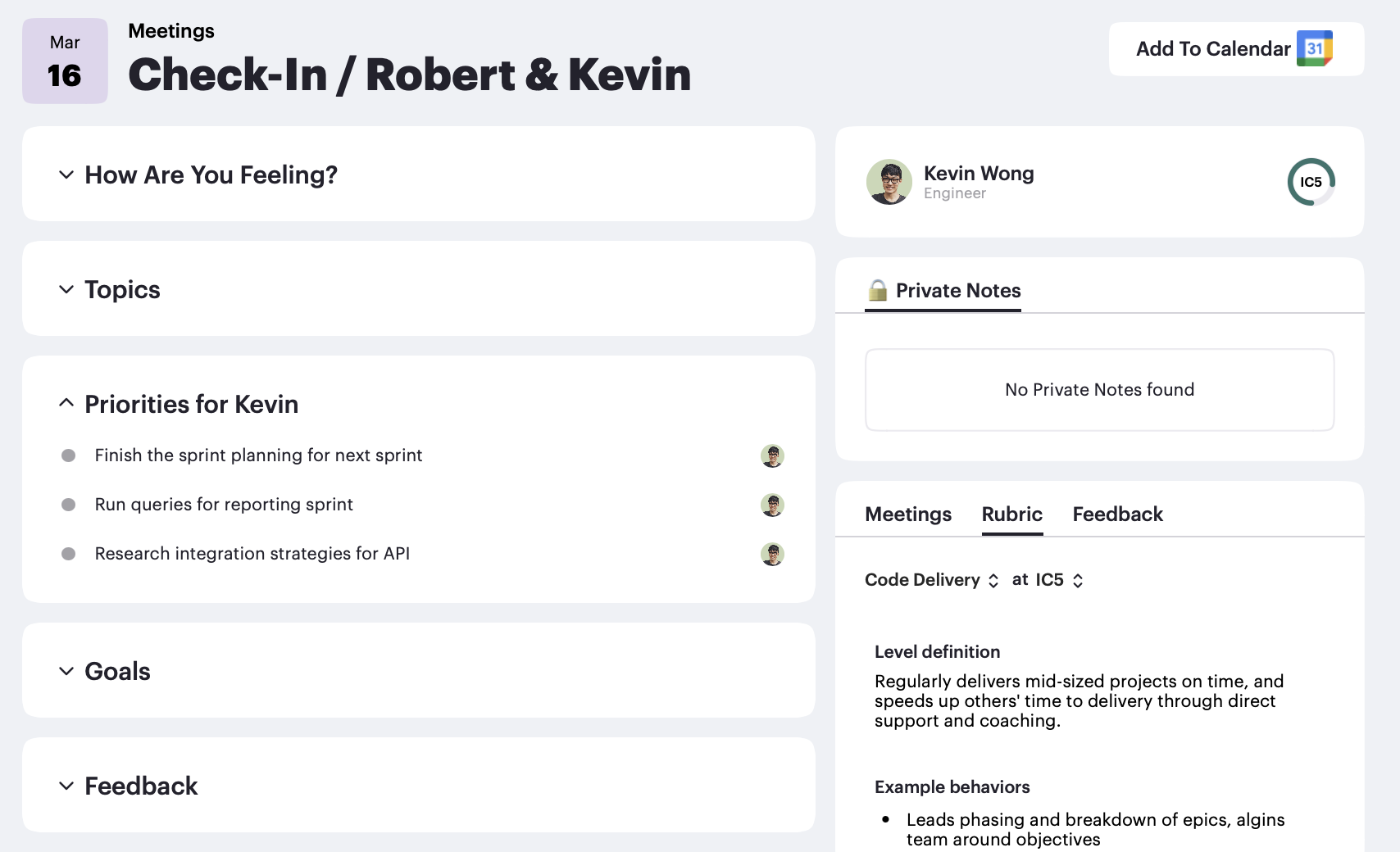
How meetings can drive structured performance based checkins to keep employees performance on track.
Read more
A CEO's perspective on how Chief People Officers can meaningfully influence leaders at the highest levels of an organization
Read more
Tips and tricks to drive employee resiliency through strategic performance programs
Read morePando unlocks the full potential of every single employee. Learn more today!
Request demo
